

Introduction:
 Photo by Dmitry Ratushny on Unsplash
Photo by Dmitry Ratushny on Unsplash

We know that dictionary is one of the fundamental structures in python language. Dictionaries exist in the core of python structures; as the class objects are partially made by dictionary containing their information. I have been using python for more than 2 years now; and I have seen some good usage of dictionaries. Recently for a project, I solved a simple sounding yet, moderately complex problem using dictionaries heavily and revised some of the notions of pythonic writing of dictionaries along wise. This article will contain some of those understanding and best ways.
What is dictionary?
If you know what a dictionary is, then please skip to next section; but we will shortly define what is a dictionary and why would you like to use once. Dictionary is a unordered collection of values which are indexed. Dictionaries are mainly used in scenarios where you want to have constant time (O(1)) lookup. In an ideal case, dictionaries do provide such a constant time lookup; but in more real scenarios, they provide a linear time lookups. Lookup time and implementation of ideal hash tables in a dictionary is out of this article; but interested one can look here.
In python3, an empty dictionary can be initiated using a simple
dict = {}
You can also create a dictionary using the python dict() command; asin
empty_dict = dict()
creates a dictionary in empty_dict. Although it is known that {} is the faster method to initiate empty dictionaries.
As I said already, a dictionary is unordered and contains values that are indexed. Each value has a unique key in a dictionary but the reverse is not same. In standard terms, we define a dictionary by key: value pairs. Let's see a normal dictionary.
Photo by Dmitry Ratushny on Unsplashnormal_dict = {"harry":2, "shyambhu":3}
In this dictionary, the strings "harry" and "shyambhu" are the keys and their values are respectively 2 and 3. For getting the values corresponding to these keys, you can use the syntax dictionary[keys] = value; i.e.
normal_dict["harry"] gives 2
normal_dict["shyambhu"] gives 3.
Now, you will also need to see all the keys and all the values. Using dictionary.keys() you can get an iterable containing all the keys. You can say print all the keys and their values like this:
for key in dictionary.keys():
print(key,dictionary[key])
But there is a better way yet to do this. And that is called the items() method of a dictionary. In such a case, you can use this:
for key,value in dictionary.items():
print(key,value)
And voila! that prints the keys and values. If you are a beginner, then you probably want to find a length of a dictionary; but there isn't one. So here our small detour to define dictionaries end.
Now, we will see little more advanced manipulations of dictionaries.
Additions of dictionaries:
One thing which is really easy in lists is that they can be added just using a "+" operator; but the same thing is not allowed for dictionaries; because of probable key collisions ( what happens if keys are same).

Now, there will be practical need of adding dictionaries. When you are certain that there is no intersection of keys; or any of the values from each dictionary is fine to keep [i.e. no dictionary is superior and it is fine to choose at random which dictionary's value to keep when a key is common]; then you can use the update() command to add two dictionaries. The way it works is:
dict1.update(dict2)
i.e. if you take a dict1 = {"harry":2, "shyambhu":3} and dict2 = {"food":10,"red":3};
then dict1.update(dict2) returns None and dict1 becomes
{"harry":2, "shyambhu":3,"food":10,"red":3}
In a more complicated scenario; if a key is common; the value in dict1 is updated from dict2 i.e. dict2's values dominate in case of key intersection. Check this example below to see how it works with these 2 one keyed dictionaries.
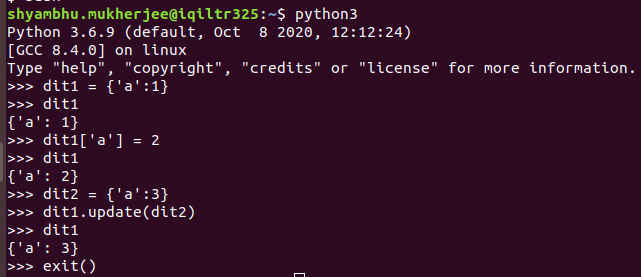
You can also; do the following:
keys1 = set(dict1.keys())
keys2 = set(dict2.keys())
key_union = keys1.symmetric_difference(keys2)
key_intersections = keys1.symmetric_difference(keys2)
for key in key_union:
#some rule
for key in key_intersections:
#some rule
where you define the rules according to your use cases. Obviously this is when the built in updates would not work. As your python code will be slower than the built-in in most cases.
Now, we will see how we can delete a dictionary entry.
deletion:
For deletion of very few, I saw a bunch of methods; like creating new dictionaries or involving loops and other things; but when you clear all the non-sense methods and focus on real usage; del is the way to go. The syntax to delete a dictionary element by key is
del dictionary[key]
This is crisp; and involves just dropping that key. If you are using something else which is definitely not faster than this, use this.
But this advise is wrong when you are deleting a significant number of keys; i.e. probably keeping only certain number of keys. In such a case, you should rewrite a new dictionary. Read this thread to understand about del in deeper level.
Next we will consider some specific dictionary creation processes; which are not that famous.
zipping and creating dict from 2 columned dataframe:
I will describe two dictionary creations; and will not comment about the speed guarantee as there maybe better methods than which I write here; but this is more on readable and small code.
scenario1:
you are given two lists and you are wondering how to create a dictionary from two lists in python. In such a case, zip comes handy. Let's say the list which is supposed to be keys is lis1 and the values are in lis2 ; and lis1[i] corresponds to its value in lis2[i].
In such a case, dict_created = dict(zip(lis1,lis2)) is the easiest solution. Now this solution is known to many among us probably; but what you may still be doing wrong is the same thing in case of a dataframe.
scenario2:
You are given a two column dataframe and you are wondering how to create a dictionary from a two column dataframe; where each row is nothing but a key followed by its value.
In such a scenario, with pandas and numpy blazing in your script; you may end up forgetting such a easy oneliner solution. But the scenario1 is nothing different from scenario2.
In this case, let's say you have a dataframe df and the two columns are lis1 and lis2; then
dict_created_2 = dict( zip( df[lis1].tolist(), df[lis2].tolist() ) )
is the easy solution to do this.
You may also employ some solution using dataframe iteration of row by row; but that will not be more efficient than this solution for most cases. I have not tested this scenario in details and therefore will not guarantee as I said before.
Conclusion:
So these are the things which I found interesting today about dictionary and revisited some of these because I forgot some of the commands. Let me know if you found this useful; and surf the index page for more contents to your liking.
Thanks for reading!
Comments
Post a Comment