

Introduction:
spaCy is a industrial library which is written on python and cython; and provides support for TensorFlow, PyTorch, MXNet and other deep learning platforms. In this post, we will explore the different things we can try with spacy and also try out named entity recognition using spaCy. In some upcoming parts, we will explore some other parts of spaCy too. Links for upcoming parts are provided below.
Before you proceed to read, if you want to read an even better introduction, read it from honnibal directly.
what all can you do with spacy?
Almost all types of normal nlp works can be done using spacy. The supported tasks are:
(1) tokenization: tokenization of sentences into word or word like tokens.
(2)POS tagging: pos tagging refers to parts of speech tagging. spacy's default language pipelines contain pos tagging and it supports pos in many languages including English.
(3)dependency parsing: dependency parsing is one of the advanced grammar actions in NLP which includes parsing a sentence to decode its structure of dependency between the words. spacy not only champions dependency parsing, but it also creates a visualization of the dependency tree.
(4) lemmatization: lemmatization is reforming a word into its base form; i.e. turning "working","worked","workable" into work. Using spacy one can perform lemmatization.
(5) sentence boundary detection: This is finding and segmenting sentences in a paragraph.
(6) Entity recognition and linking: this is labeling words in text copy as real world objects as "person","location","organization" etc; as well as taking reference from a universal corpus for linking the entities present in text.
(7) text classification: spacy can be used to run text labeling and classification actions.
(8) Rule based matching: spacy can be used to find specific parts of speech based patterns. It is also called chunking.
(9) Training: spacy can be also trained ( one of the main objective too) to create custom models by training on your data as well as creating new model objects. Spacy also facilitates serialization for saving the custom trained models.
These are the different tasks spacy can very well perform. Now, in the next section, we will go through the basic training of spacy available in spacy website and mention the brief, important points for you to become well trained in spacy.
Basic NLP training walk-through:
from spacy.lang.en import English
nlp = English()
text = "I want to learn spacy and nlp."
doc = nlp(text)
Clearly, here English is a language object for text processing in english. If you want to do any kind of work in spacy and language english, then you will most probably need to do this step of importing english and then loading the object into nlp.
Although in practice, for even moderately long texts, this nlp(text) line completes in milliseconds, this step is actually quite elaborate. The text is tokenized, pos tagged, ner tagged and stored into doc. Because of highly optimized algorithms of spacy, these happen so fast. In part 2, we will learn properly about how these processes work.
For now, let's see some code snips about how the same thing works for other languages too.




In the above example, after processing the text using nlp object; we loop through the doc treating it as an iterable, and then use like_num and text attribute of the tokens; to find out percentages.
You could have achieved something similar using a complex regex pattern ( \d+%) but once we get into depth you will see how spacy offers much more than simple regex alternatives.
Let's see how spacy provides more information about each token; on pos,dependency and others.

Clearly as you can see, using pos_ and dep_ attributes, you can respectively find out the pos tag the spacy assigns as well the position of the token in the dependency tree of the sentence. We will discuss the dependency tree and dependency parsing basics in another post, so no need to get concerned about that for now.
Let's also see how to parse the entities identified in the text by spacy ner.

As, I was discussing earlier, other than being an iterable of tokens, doc object also has other attributes; like .ents. ents store the entities which are either tokens or a sublist of doc( called span in spacy terminology) and can be used by their label_ attribute to see their detected entities.
This is important to note that, entity tagger, pos tagger and some other models which spacy uses to do these tasks; are statistical models. Therefore, you will see wrong or missed entity tagging in some amount also. For those you have to manually handle like below:

One more point I will like to note at this point that, often one lands into spacy for entity tagging first time. They read about ner and spacy; try out coding.. and the things go south because of not understanding the flow in which spacy works.
I got this error when I tried spacy ner without using the flow:
ValueError: [E109] Model for component 'ner' not initialized. Did you forget to load a model, or forget to call begin_training()?
If you follow the above simple procedure of (a) process the text (b) use the ents attribute to get the entities; then such value errors will not occur.
Now, let's discuss the last and final portion of part 1 of our spacy exploration; which is the usage of matcher api from spacy.
Basically matcher works on defining patterns of phrases; which then runs through the text and finds out the matches accordingly. These types of matching is really useful in case of information extraction and data science applications; for many reasons.
We will first show you a basic example of calling the matcher attribute and how it works and then go on to discuss the specifics.

So for using matcher; there are four things you need to do:
(1) call the Matcher class from spacy.matcher
(2) provide the vocab from the nlp object to matcher and initialize the matcher instance
(3) Write the pattern using the following structure:
pattern = [{attribute_of_token: equate_to_this}, {attribute_of_next_token: equate_to_this}...]
now this is the most tricky thing about the matchers. Let's say you want to match the word "amazon" case-insensitively. Then what attribute of a token should match to what so that your match is covered always?
the answer is that the .lower attribute of the token should always be equal to "amazon". Then, the pattern portion related to this will be:
pattern_name = [{"LOWER": "amazon"}]
which will now look at the lower attribute of each token; and if that matches to "amazon", then it will record that match.
This part is tricky and needs practice as well as example. The example we'll provide you soon.
(4) Now once you have the pattern written; you have to add that to the matcher object initiated. That is done in the below way:
matcher.add(match_name,None, pattern_name)
And voila! your work is done. Now, you can directly apply matcher on doc and you will get the matches. The loop part to see/print the matched texts after that is very much straightforward.
As I said, matching is tricky; and that's why we will provide some examples of this. You will notice that, you can also provide POS instead of direct texts or lower version of it; as well as lemmatized version of a text, so that you can get all the versions in which the root is present. Now without further ado:
(a) example of matching complex patterns:
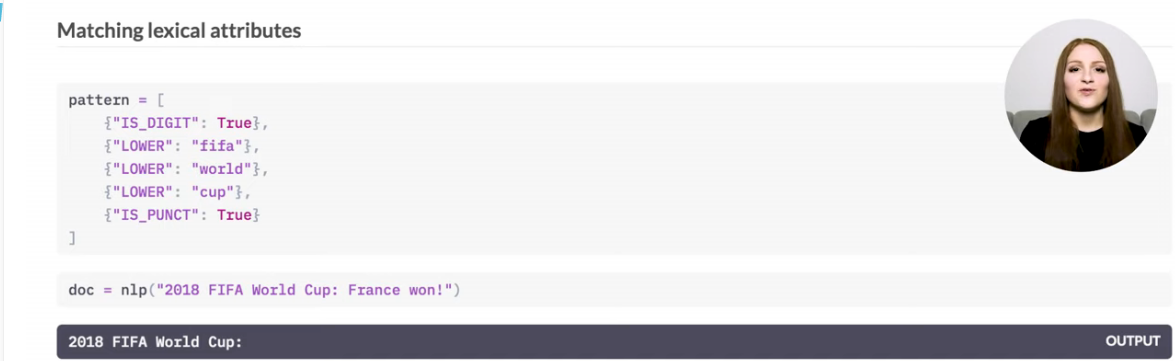
Here we are trying to find all patterns; that start with a number, follows by "fifa world cup" and ends in a punctuation.
See that you can not write more than one token inside a {} in case of writing a pattern for matcher class. In case of phraseMatcher, which we will describe in part2, you will be allowed to do so.
[ the woman in the picture is the instructor for spacy course: ines montani, cofounder of spacy and core-developer of spacy as well as prodigy the annotation tool]
(2) example of matching pos based patterns:
In this example, we are trying to match different versions of the root "love", occuring as a "verb", followed by a Noun.
Observe the fact, that you can actually provide multiple attributes in a pattern if they are for matching one pos. This helps to specifically find patterns and can't be achieved either by regex or string searches, pos searches and lemma searches on their own. Therefore, spacy clearly dominates the phrase search with higher complexities.

(3) Using optional for extending search patterns:
In this case, we want to search all versions of the root "buy", followed a noun, with/without a determiner within them. Now as the presence of determiner is optional, therefore we need to explicitly state that.
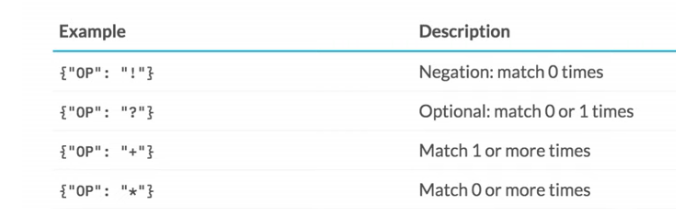
In such a case, optional parameter, or the key "OP" comes in handy.

Now, you may wonder what are values you can set for "OP" and do they always mean optional presence one time? obviously not. Turns out, you can actually use "OP" key to avoid, check presence strictly once or never, or strictly more than once and so on. Check out the OP rules snippet below.



Further readings and questions:
part (2) what is dependency parsing?
part (3) How to manipulate and create spacy's pipeline and custom pipelines
Part (4) How to train neural network models using spacy
Generic open questions:
what is a simple turning method?
Comments
Post a Comment